이루다 개발사 "데이터 전량폐기 안한다"
14일 정보기술(IT)업계에 따르면 스캐터랩은 전날 밤 사과문과 추가 입장문을 발표했다. 이 회사는 이용자 중 AI 학습에 데이터가 활용되는 것을 원하지 않는 사람들의 카카오톡 대화는 개인정보보호법에 따라 데이터베이스(DB)에서 삭제하겠다고 밝혔으나 데이터 전량 폐기를 언급하지는 않았다. 대화 상대방인 제3자의 동의를 거치지 않았다는 지적에 회사 측은 “내부적으로 문제가 없을 것으로 판단했다”고 답했다. 연애의 과학 이용자와 시민단체들은 스캐터랩이 제대로 된 동의 절차를 거치지 않았으므로 대화 데이터를 모두 폐기해야 한다는 입장이다.
깃허브를 통해 유출된 개인정보 등의 문제에 대해 스캐터랩 측은 “개발팀이 2019년 깃허브에 공개한 내용에 대화 데이터가 포함된 사실이 확인됐다”며 “해당 깃허브 게시물은 즉시 비공개 처리했다”고 설명했다.
그러나 스캐터랩의 게시물을 포크(공유)한 게시물에 대해 개발자 커뮤니티에서는 우려가 나온다. 이미 깃허브 외부 크롤러 봇(온라인상에서 자료를 자동 수집·보존하는 프로그램)에 의해 국내외로 유출됐을 가능성도 점쳐지고 있다.
김남영 기자 nykim@hankyung.com
-
기사 스크랩
-
공유
-
프린트
-
1
"AI 농장 3km 모두 살처분"…비과학적 방역 밀어부친 정부
경기 안성시 금광면의 한 토종닭 농장. 이 농장은 1989년부터 지금까지 한약재와 자연약초를 배합해 고급육 생산을 해왔다. 일반 계사가 아닌 평사에서 자유롭게 기르는 닭으로 일반 농장보다 30일 이상을 더 키워 출하한다. 이 농장은 미생물을 혼합해 만든 한방 사료로 지금까지 고병원성 조류인플루엔자(AI) 감염 없이 농장을 운영했다. 13일 이 농장에는 청천벽력같은 전화가 걸려왔다. 2.8km 떨어진 한 산란계 농가에서 AI양성 판정이 나와 1만 마리의 닭과 병아리를 곧장 살처분 해야 한다는 통보였다. 이 농장의 조 모 대표는 "우리 농장은 3면이 산으로 둘러싸여 있어 발생 농장과 생활 반경이 명백히 구분되는 데다 철새 도래지 하천과도 상당한 거리가 있다"며 "소규모 도계장을 운영해 농장 소유의 닭만 취급하는데 단순 거리로만 계산해 음성 판정을 받고도 무조건 살처분 해야 한다는 것은 용납하기 어렵다"고 밝혔다. 토종닭협회와 농장주 등은 경기도에 살처분 대상 조정을 재평가 해달라는 건의서를 제출했다. '3km 이내 무조건 살처분' 반발AI가 전국으로 번지고 있는 가운데 정부의 '3km 이내 살처분' 규정의 개선을 요구하는 가금 사육농가와 단체들의 성명이 곳곳에서 잇따르고 있다. 살처분 규정은 그 동안 반경 500m 이내 범위였다가 2019년 말 3km로 개정되면서 혼선이 가중됐다. 농장주 중엔 “살처분 대상이 될 지 전혀 몰랐다”는 곳도 많다.특히 현행 규정상 범위가 직선 거리로 계산돼 실제 거리가 더 멀더라도 살처분 대상에 속한다. 11일 기준 살처분 가금류 수는 약 1502만 마리에 달한다. 이 가운데 75%(1133만마리)가 예방적 차원에서 살처분됐다. AI검사에서 음성이 나왔더라도 직선 반경 3km 이내 있었다는 이유로 살처분 됐다는 뜻이다. 화성시에서 산란계 3만7000마리를 사육하는 산안농장은 지난 5월 수원지법에 살처분 집행정지 가처분 신청을 내기도 했다. 반경 3km 이내 산란계 농장에서 AI가 발생해 26일까지 살처분 하라는 행정명령을 받은 데 대한 것이다. 영국 네덜란드 등은 농장별 심사 후 살처분 결정 농장주들은 현행 정부의 예방적 살처분 조치가 외국의 사례와 견줘 과도하다고 지적하고 있다. 한국육계협회에 따르면 미국·이탈리아·일본 등은 주로 발생농가에 한해 살처분을 실시하고 역학 농가는 정밀검사 후 문제가 있는 경우에만 시행한다.영국은 발생 농장으로부터 전파 가능성이 높은 농장에 대해 면밀히 위험평가를 한 후 예방적 살처분을 한다. 강력한 AI 방역대책을 펼치는 네덜란드도 반경 3㎞ 이내 농가에 대해 AI 검사를 진행한 뒤, 반경 1㎞ 이내 농가에 대해서만 예방적 살처분을 시행하는 것으로 알려졌다. 방역 대책을 철저히 세우는 것은 좋지만 축산업의 형태와 지형적 여건, 야생조수류 서식실태와 역학적 특성 등 위험도 평가를 더 세심하게 할 필요가 있다는 지적이다. 축산업계 관계자는 “먹거리 안보, 물가 안정 등을 감안해 보완돼야 할 것”이라며 "농장마다 처한 지역적 환경과 사육 방식 등이 다 다른데 매년 반복되고 있는 AI를 천편일률적인 잣대로 방역 대책을 세우고 있어 그 피해를 농장과 멀쩡한 닭들이 입고 있다"고 지적했다.김보라 기자 destinybr@hankyung.com

-
2
냉장고 음식으로 레시피 추천…CJ올리브, LG전자와 AI 서비스
CJ올리브네트웍스가 14일 세계 최대 IT·가전 전시회 ‘CES 2021’에서 개인 맞춤형 레시피 추천 인공지능(AI)인 ‘레시픽(Recipick)’을 선보였다.레시픽은 CJ올리브네트웍스가 LG전자와 협력해 만든 기술로 CES 2021 ‘LG 퓨처톡’ 행사에서 공개됐다. 냉장고 안에 있는 식재료와 축적한 사용자 데이터를 조합해 고객 맞춤형 레시피를 추천하는 AI 기술이다. 앱을 연동해 실시간으로 냉장고 내 식재료를 파악할 수도 있다. CJ올리브네트웍스는 다양한 고객 행동 데이터를 결합해 사용자의 생활에 맞춘 식품 및 레시피 추천 기능을 고도화할 계획이다.
-
3
LG CNS가 정보기술(IT) 전문 블로그인 ‘크리에이티브앤스마트(Creative&Smart)’의 누적 방문자 수가 개설 8년 만에 1000만 명을 돌파했다고 14일 발표했다.2012년 문을 연 크리에이티브앤스마트 방문자 수는 2015년 처음 누적 100만 명을 넘어섰다. LG CNS는 블로그에서 IT 관련 콘텐츠를 매주 5회 내놓고 있다. 디지털 전환 적용 사례와 IT 신기술 등 2400건이 넘는 콘텐츠가 쌓여 있다. LG CNS는 블로그 누적 방문자 1000만 명 돌파를 기념해 오는 31일까지 감사 이벤트를 진행한다. LG CNS 블로그에서 가장 인상 깊었던 콘텐츠 다섯 가지를 선정해 응모하는 방식이다. 추첨을 통해 노트북 등을 선물한다.김주완 기자 kjwan@hankyung.com
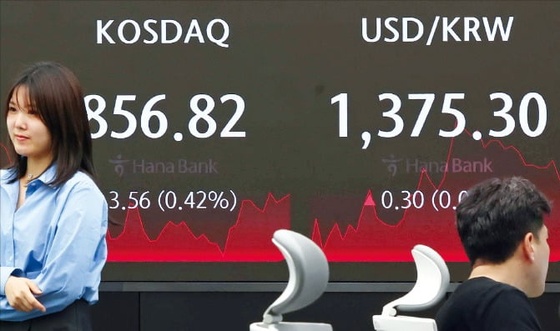
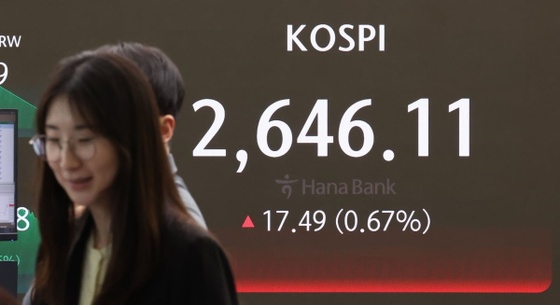
![구글, 사상 첫 배당 '주당 20센트'…AI 불안감 덮었다 [글로벌마켓 A/S]](https://timg.hankyung.com/t/560x0/photo/202404/B20240426073327760.jpg)








