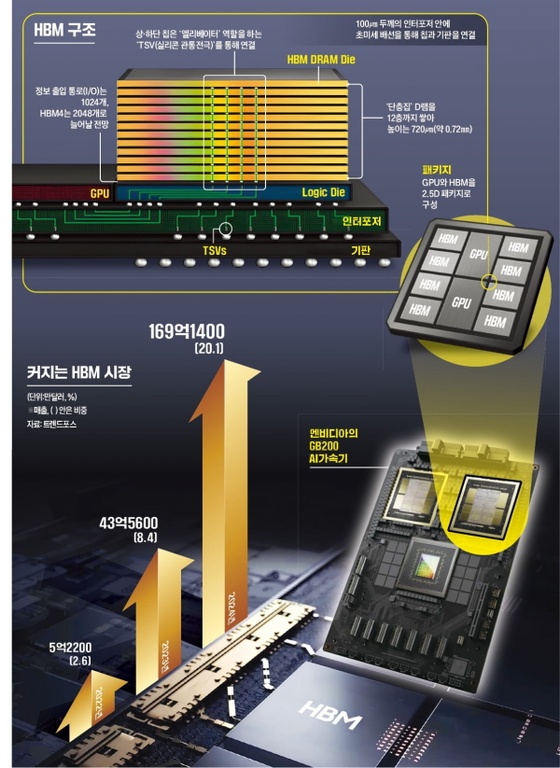
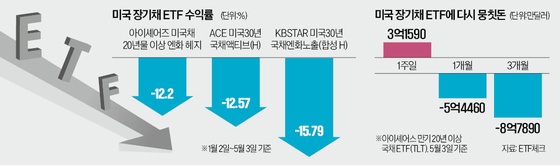
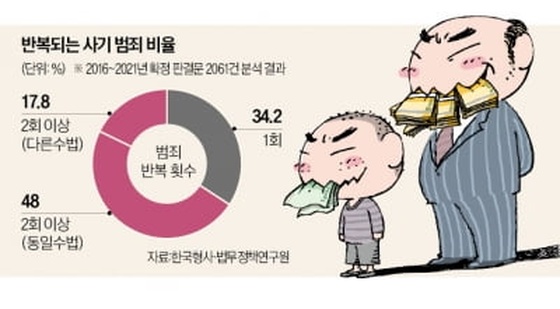
오픈AI "추론단계별 보상훈련 통해 AI의 잘못된 정보 제공 개선"

오픈AI는 이날 발표한 연구 논문에서 "AI 모델이 정답에 도달했을 때 올바른 최종 결론을 스스로 보상하도록 하는 것이 아니라, 각각의 올바른 추론 단계에 대해 보상하도록 훈련"함으로써 환각을 개선할 수 있다고 설명했다.
환각은 AI가 잘못된 정보를 마치 사실인 것처럼 제공하는 것을 의미한다.
논문은 "심지어 최첨단 모델도 거짓을 만들어내는 경향이 있다"며 "이는 불확실한 순간에 사실을 지어내려는 경향을 보여준다"고 설명했다.
이어 "이런 환각은 다단계 추론이 필요한 영역에서 특히 문제가 된다"며 한 단계에서 논리적 오류가 발생하면 단계를 거치면서 더 큰 오류를 초래할 수 있기 때문이라고 덧붙였다.
연구원들은 이에 "AI 모델이 최종 결론에 대해서가 아니라, 각각의 올바른 추론 단계에 대해 보상하도록 훈련하는 것"이 필요하다고 강조했다.
그러면서 이런 접근 방식을 "결과 감독"(outcome supervision)과 반대되는 "과정 감독"(process supervision)이라고 언급했다.
논문은 "이 방식은 AI 모델이 인간과 유사한 사고 과정을 따르도록 촉진하기 때문에 이를 통해 더 나은, 설명 가능한 AI가 될 수 있다"라고 설명했다.
그러나 이에 대해 회의적인 시각도 있다고 미 경제매체 CNBC는 전했다.
전자 개인정보센터의 AI 및 인권 프로젝트 책임자인 벤 윈터스는 "이것만으로는 AI의 잘못된 정보와 결과에 대한 우려를 완화하기는 어렵다"고 말했다.
미 브라운대학교의 기술 책임센터장인 수레시 벤카타수브라마니안은 "대규모 언어 모델이 작동하는 방식이 전반적으로 불안정하기 때문에 어떤 환경에서는 작동한다 해도, 다른 환경에서는 작동하지 않을 수 있다"고 지적했다.
/연합뉴스
-
기사 스크랩
-
공유
-
프린트
-
1
기름값 비싸다 했더니...美석유기업 사우디와 내통 의혹 [원자재 이슈탐구]
엑슨모빌과 파이어니어 FTC 독과점 심사에서 적발물가 안정 위해 기름값 잡으려던 美 정부 충격 자국 셰일가스 기업 밀어줬더니 배신미국 셰일 기업이 사우디아라비아가 주축인 석유수출국기구(OPEC)와 내통했다는 의혹이 제기됐다. OPEC과 정보를 교환하며 석유 생산량을 적절히 조절해 유가를 밀어 올렸다는 얘기다. 미국 연방거래위원회(FTC)가 엑손모빌과 파이어니어의 595억달러 규모 인수·합병(M&A) 관련 독과점 가능성을 심사하던 도중, 이 같은 혐의가 포착됐다.혐의가 사실로 밝혀질 경우 물가를 안정시키려던 조 바이든 대통령 행정부와 민주당에는 큰 충격이 될 전망이다. 바이든 행정부는 오는 11월 대선을 앞두고 석유 생산을 늘려 물가를 끌어내리려고 셰일 업계를 은밀히 지원했다. 덕분에 미국 석유기업들은 막대한 이득을 얻기도 했다. 미국 에너지 업계의 대형 M&A가 이어지는 가운데 미 정부의 감시는 더욱 엄격해질 것으로 예상된다. 원유를 100% 수입하는 한국과 일본 등에는 호재라는 분석도 나온다. 파이어니어 전 사장 엑슨모빌 합류 금지한 FTCFTC는 지난주 세계 최대 석유기업 엑슨모빌이 미국 대형 셰일가스 기업 파이오니어 인수를 조건부 승인했다. FTC의 거래 승인 조건은 "스콧 셰필드 전 파이오니어 최고경영자(CEO)가 합병 후 엑슨모빌 경영진에 포함돼선 안 된다"는 것이다. 로이터통신에 따르면 1997년 파이오니어를 설립한 셰필드 전 CEO는 글로벌 석유·가스 업계의 마당발이다. 미국 석유·가스 기업 경영자들과 친할 뿐 아니라 OPEC 회원국 관계자들과도 거의 연례적으로 만찬을 가져왔다.그는 2016년 은퇴했으
![기름값 비싸다 했더니...美석유기업 사우디와 내통 의혹 [원자재 이슈탐구]](https://img.hankyung.com/photo/202405/01.36629554.3.jpg)
-
2
스타벅스·맥도날드 안 가는 미국인들 "가격 너무 올랐다"
스타벅스와 맥도날드 등 미국의 대형 식음료 브랜드들이 잇따른 가격 인상 후 소비자들의 외면을 받고 있다.5일(현지시간) 월스트리트저널(WSJ)은 코로나19 팬데믹 후 식품 회사들은 소비자들의 충성도가 변하지 않을 것으로 기대하며 비용 증가에 대응해 급격한 가격 인상을 단행했다가 외면받고 있다고 보도했다. 예컨대 올해 3월 웬디스나 맥도날드 등 패스트푸드 가격은 2019년에 비해 33%나 상승했다.인플레이션에 시달리는 미국 소비자들은 일상적으로 이용하던 식음료에서 가격 부담을 크게 느끼고 있다. 캘리포니아주 라구나니구엘에 사는 데니스 몬테나로(75)는 최근 맥도날드에서 가장 좋아하는 메뉴인 베이컨과 달걀 베이글과 커피를 주문했다가 9.67달러(약 1만3000원)가 찍힌 영수증을 보고 "이제 패스트푸드는 끝이다"라고 다짐했다고 밝혔다.실제로 시장조사업체 레비뉴매니지먼트솔루션에 따르면 올해 1분기(1~3월) 미국의 패스트푸드 이용객은 전년 대비 3.5% 감소했다. 이용객 감소는 기업 실적에 고스란히 반영됐다. 맥도날드의 올 1분기 주당 순익은 2.7달러로 시장 예상치인 2.72달러보다 낮았다. 맥도날드 경영진은 저소득층을 중심으로 지출 억제 분위기가 뚜렷하다며, 최근 소비 감소세는 놀라울 정도라고 경고했다. 스타벅스 역시 지난달 30일 실적 발표에서 1분기 스타벅스의 미국 매장 방문객 수가 7% 급감했다고 발표했다.캘리포니아주 엘도라도힐스에 사는 변호사 데이비드 마이클(58)은 기존엔 거의 매주 맥도날드를 먹었지만 얼마 전 탄산음료 가격이 1달러에서 1.69달러까지 오른 걸 본 뒤 몇 달째 가지 않고 있다고 말했다. 스타벅스도 톨 사이즈 카페모카 가격이 5.25달러까지 오른

-
3
싱가포르의 인터컨티넨탈 호텔이 투숙객을 상대로 기발한 투숙 상품을 출시했다.싱가포르 인터컨티넨탈 호텔은 고객이 호텔에 머무는 동안 비가 오면 투숙 기간 중 하루를 배상해 주는 'Rain Resist Bliss(反반-기우제)'상품을 선보였다.가포르는 1년에 평균 171일이 비가 오는 강수량이 많은 나라다. 안드리스 크레머(Andreas kraemer) 호텔 총지배인은 "여행의 질은 좋은 날씨로부터 시작한다. 잦은 비로 인한 여행객들의 불편함을 해소하고자 기획했다"고 밝혔다.해당 상품을 활용하려면 호텔 측에서 요구하는 일정 조건을 충족해야 한다. 일단 투숙객이 스위트 룸 이상의 객실에 투숙해야 한다. 또 오전 8시부터 저녁 7시까지 비가 내리는 시간이 누적 120분을 초과해야 한다. 다만 비가 내리기 시작한 시점으로부터 4시간 이내에 측정된 시간만 인정받을 수 있다. 예를 들어 오후 4시부터 오후 5시 30분(90분) 사이에 비가 내리고, 오후 6시부터 오후 6시 30분(30분) 사이에 비가 계속 오면 환불이 가능하다.조건을 갖춘 투숙객에게는 상품권을 지급한다. 이 상품권은 싱가포르 인터컨티넨탈 호텔에서만 6개월 이내에 사용해야 하며 비용은 투숙객이 묵었던 객실 상품과 동일한 가격으로 제공한다.장지민 한경닷컴 객원기자 newsinfo@hankyung.com