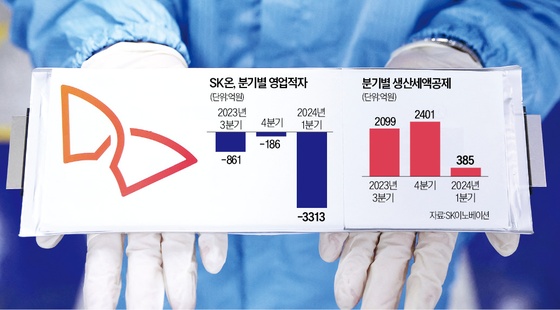
가천대 연구팀 "챗봇 GPT-4, 한의사 국가시험 통과 수준 성능"

이 연구 결과는 온라인 과학 저널 '플로스 디지털 헬스'(PLOS Digital Health)에 실렸다.
연구팀은 GPT-4 모델을 한의학 인공지능 개발에 적용할 수 있을지 등을 평가하기 위해 이번 연구를 진행했다.
앞서 연구에서는 GPT-4가 2022년 시행된 한의사 국가시험에서 평균 57.59%의 정답률을 기록해 합격선(60% 이상)에 약간 못 미쳤으나 이번 연구에서는 GPT-4의 언어모델에 문항을 제시하는 방식을 최적화해 모델의 성능을 극대화하는 기법인 '프롬프트 엔지니어링'을 활용했다.
그랬더니 이번 시험 결과에선 합격선을 웃도는 정답률을 보였다.
2022년 한의사 국가시험 문제를 GPT-4에 제시한 뒤 정답률을 평가했는데 GPT-4는 340문항 중 225문항을 맞혀 66.18%의 정답률을 나타냈다.
과목별 정답률도 과락 기준인 40%보다 높게 나왔다.
GPT-4는 과목별 정답률의 편차가 크게 나타났는데 국제적으로 표준화된 진단기준에 대한 문제가 주로 출제된 본초학, 소아과학, 부인과학 과목은 81.2%, 81.2%, 79.2%의 높은 정답률을 보였다.
반면 한국 한의학의 특성을 반영하는 보건의약관계법규, 사상의학 과목은 40.0%, 43.8%로 상대적으로 낮은 정답률을 나타냈다.
연구팀은 "한국어로 된 문항을 언어모델에 그대로 입력했을 때는 평균 정답률이 51.82%였는데, 한의학 용어를 한자로 함께 적었을 때는 57.59%, 지시와 문제를 영어로 스스로 번역하게 한 뒤 이 문제를 풀게 했을 경우는 63.65%로 상승해 정답률이 높아지는 것을 확인했다"라고 말했다.
그러면서 "이번 연구에서 GPT-4는 한국의 특수성을 잘 반영하지 못할 수 있다는 점을 보였다"라며 "추후 의료 인공지능 모델을 개발할 때 각 국가와 지역의 특수성을 반영할 수 있는 노력이 필요할 것으로 보인다"라고 밝혔다.

-
기사 스크랩
-
공유
-
프린트
-
1
"박태환이 친 골프공에 망막 손상"…법원도 '무혐의' 내렸다
수영 스타 박태환(35)이 골프를 치다 실수로 옆 홀 내장객의 머리를 공으로 맞혀 다치게 한 혐의로 피소됐지만, 경찰, 검찰에 이어 법원에서도 무혐의 판단을 받았다.29일 법조계에 따르면, 서울고법은 지난 26일 다친 내장객이자 고소인인 A 씨가 낸 재정신청을 기각했다.재정신청은 고소·고발인이 검찰의 불기소 처분에 불복하면 법원에 대신 판단을 내려달라고 요청하는 것이다. 법원이 재정신청을 받아들이면 검찰은 공소를 제기해야 하는데, 기각해 무혐의로 결론짓게 됐다.A 씨는 2021년 11월 강원도 한 골프장에서 골프를 치던 중 옆 홀에서 플레이하던 박태환이 친공에 맞아 눈과 머리 부위를 다쳤다며 박태환을 과실치상죄로 고소했다. 박태환은 합의하려 했으나 당시 합의에는 이르지 못했다.고소장을 접수한 경찰은 그러나 박태환에게 혐의가 없다고 판단해 불송치했다.A 씨는 이의신청했고, 사건을 다시 살핀 춘천지검 역시 불기소 처분을 내렸다.검찰은 박태환이 당시 경기보조원(캐디) 지시에 따라 타구한 점과 아마추어 경기에서 슬라이스(공이 타깃 방향의 오른쪽으로 심하게 휘어지는 것) 구질이 흔하게 발생하는 점 등을 이유로 박 씨에게 죄를 묻기 어렵다고 봤다.A 씨는 검찰의 불기소 처분에 반발하며 항고했으나 지난해 11월 기각당했으며 재정신청도 이와 같은 결론을 얻게 됐다.장지민 한경닷컴 객원기자 newsinfo@hankyung.com

-
2
"식당 손님이 가방 놓고 갔어요"…열어 보니 흰 가루가 '발칵'
식당 손님이 식당에 필로폰이 든 가방을 놓고 자리를 떴다가 마약 소지 혐의로 체포됐다.29일 서울 동대문경찰서는 50대 남성 A씨를 마약류관리에 관한 법률 위반 혐의로 수사 중이라고 밝혔다.A씨는 가방에 필로폰을 소지한 혐의를 받고 있다. 현행법상 마약은 소지하는 것만으로도 처벌받는다.경찰은 앞서 23일 동대문구 제기동 식당 직원으로부터 "손님이 가방을 두고 갔다"는 유실물 습득 신고를 받았다. 경찰은 가방을 열고 소지품을 확인하다 필로폰 가루를 발견했다.A씨의 지인 B씨는 다음날 A씨의 부탁을 받고 유실물을 찾으러 파출소를 찾았다.경찰이 필로폰 입수 경위를 묻자 "내 물건이 아니라 A씨의 것"이라 말한 것으로 확인됐다. 이후 A씨는 가방을 찾으러 관할 파출소를 찾았다가 입건됐다.A씨는 경찰 조사에서 "마약이 맞긴 하지만 친형이 갖고 있던 걸 내가 가방에 넣어놓고 있었다"고 진술한 것으로 확인됐다. 그는 마약류 간이시약 검사에서 필로폰 음성 반응이 나왔고 현재 국립과학수사연구원의 정밀 검사를 기다리고 있다.한편, 경찰은 A씨 진술의 사실 여부를 판단하면서 서울 도심에 마약이 유입된 경위에 대해 수사를 확대할 방침이다.장지민 한경닷컴 객원기자 newsinfo@hankyung.com

-
3
제주서 만취해 130㎞로 질주한 30대 여성…동승자는 사망
제주도에서 음주 상태로 렌터카를 몰다가 사고를 내 동승자를 사망하게 한 30대 여성이 검찰에 넘겨졌다.29일 제주서부경찰서는 음주운전과 위험운전치사 혐의로 30대 A씨를 검찰에 송치했다고 밝혔다. 제주도로 여행을 왔던 A씨는 지난달 15일 오후 11시47분쯤 제주시 한림읍에서 음주운전을 하다 사고를 내 조수석에 타고 있던 30대 남성 B씨를 숨지게 한 혐의를 받고 있다.사고 차는 일명 '오픈카'라고 불리는 컨버터블 차량이었다. 당시 A씨는 시속 130㎞로 질주하다 전신주를 들이받았고 사고 충격으로 전신주가 쓰러지면서 B씨를 덮친 것으로 조사 결과 알려졌다. 경찰 조사 결과 A씨 혈중알코올농도는 면허취소 수치(0.08% 이상)인 것으로 전해졌다. 장지민 한경닷컴 객원기자 newsinfo@hankyung.com


![34년만 엔·달러 환율 160엔 돌파…환율 출렁인 이유는? [한경 외환시장 워치]](https://timg.hankyung.com/t/560x0/photo/202404/01.36562723.1.jpg)