네이버 하이퍼클로바X 학습 기준 깜깜…블로그 비중이 1위?

1일 자연어처리기술(NLP) 학회 EMNLP에 2021년 채택된 하이퍼클로바 관련 연구 논문에 따르면 하이퍼클로바는 5천618억 토큰(데이터에서 의미를 가지는 최소한의 덩어리)을 사전 학습했다.
이 가운데 블로그(2천736억 토큰)의 비중이 가장 높았으며 이어 온라인 카페(833억 토큰), 뉴스(738억 토큰), 댓글(411억 토큰), 지식인 서비스(273억 토큰) 등의 순이었다.
토큰은 AI 학습용으로 모아둔 일종의 '말뭉치'(Corpus·특정한 목적을 가지고 수집한 텍스트 데이터)로, 문장을 만들어내는 데 사용되는 토큰이 많아질수록 생성형 AI의 연산 과정·시간도 길어진다.
국립국어원이 만든 '모두의 말뭉치'처럼 이미 만들어진 AI 학습용 한국어 데이터 세트는 고품질 출처로 간주해 하이퍼클로바 학습 데이터에 포함됐다.
이 밖에 하이퍼클로바는 다양성 확보 차원에서 일부 전문 지식도 학습했다.
네이버에 따르면 이렇게 만들어진 한국어 데이터 세트는 1.96테라바이트(TB) 크기다.
한국어 위키피디아의 2천900배로, 한국어 뉴스 50년 치에 해당한다.
네이버 관계자는 "모든 AI는 고정된 모델이라기보다는 '지식 체계'로, 계속해서 업데이트된 데이터를 학습하며 고도화되는 것이 특징"이라며 "하이퍼클로바의 사전 학습 데이터를 하이퍼클로바X의 현재 학습 데이터로 간주할 수는 없다"고 설명했다.
그러면서 "하이퍼클로바X에서는 법률, 수학, 논문 등의 다양한 전문 데이터 확보를 지속해서 강화해 나갈 계획"이라고 덧붙였다.
최근 생성형 AI 개발 붐이 일면서 국내외에서 AI 학습을 위해 뉴스 등의 콘텐츠를 공짜로 사용하는 데 대한 반발이 거세지는 가운데, 네이버는 별도의 저작권 사용료에 대해 논의하고 있는 단계가 아니라는 입장을 밝혀 논란을 빚고 있다.
네이버는 지금까지 하이퍼클로바X가 약관에 근거해 뉴스, 블로그 등을 학습했다고 주장한다.
이에 반해 챗GPT 개발사 오픈AI는 지난 7월 미국의 뉴스 통신사 AP통신과 뉴스 기사 사용 등에 관한 라이선스 계약을 체결하며 대비를 이뤘다.
/연합뉴스
-
기사 스크랩
-
공유
-
프린트
-
1
"굳이 이 돈 내고 볼 이유가…" 잘 나갔던 유료방송 '눈물'
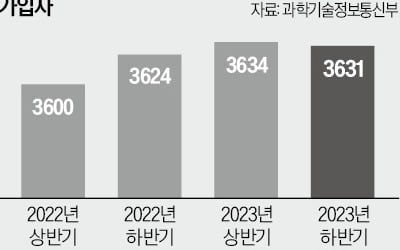
국내 유료 방송 가입자가 관련 통계를 집계한 이후 처음으로 감소했다. 넷플릭스, 쿠팡플레이 등 온라인동영상서비스(OTT) 이용이 늘면서 유료 방송을 해지하는 ‘코드 커팅’ 현상이 나타났다는 분석이 나온다. 늘어나는 1인 가구 수요에 힘입어 성장하던 인터넷TV(IPTV) 서비스 시장이 한계에 봉착한 게 아니냐는 우려가 커지고 있다.과학기술정보통신부는 2023년도 하반기 유료 방송 가입자 수와 시장점유율을 16일 발표했다. 조사 결과에 따르면 작년 하반기 유료 방송 가입자는 3631만106명으로 전기 대비 3만7389명(0.1%) 감소했다. 유료 방송 가입자가 줄어든 것은 이 조사가 이뤄진 2015년 하반기 이후 처음이다.IPTV 가입자는 2092만5902명으로 전체의 57.63%에 달했다. 다른 유료 방송과 달리 증가세를 유지했지만 증가폭이 점차 줄어드는 추세다. 2020년 하반기 IPTV 가입자의 전기 대비 증가율은 4.38%에 달했지만 2022년 하반기에는 1.79%, 작년 하반기에는 0.54%로 낮아졌다. 케이블TV(SO) 가입자는 1254만1500명으로 작년 상반기보다 0.71% 줄었다. 위성방송 가입자도 2.04% 감소한 284만2704명에 그쳤다.사업자별로는 KT가 882만7392명(24.31%)으로 가장 많았다. SK브로드밴드(IPTV)가 668만4857명(18.41%), LG유플러스가 541만3653명(14.91%)으로 2위와 3위에 올랐다.시장조사업체 컨슈머인사이트가 국내 19세 이상 유료 방송 이용자 2만여 명을 대상으로 조사해 올해 초 발표한 자료에 따르면 유료 방송 이용자의 37%가 유료 방송을 해지하고 OTT를 이용하는 코드 커팅을 고려하고 있는 것으로 나타났다.코드 커팅을 고려하는 이유로는 ‘TV를 보는 일이 줄어서’(31%)와 ‘TV에 볼 만한 것이 별로 없어서’(30%)라는 답변이 가장 많았다.
-
2
텍스트 검색시대 '끝'…"마케팅 전략 다시 짜야" 경고 나왔다
네이버의 인공지능(AI) 챗봇 ‘클로바X’에서 ‘이번주 토요일 강화도에서 성인 2명과 아이 1명에게 어울리는 10만원 이하 숙소’라고 입력하면 키즈 펜션, 글램핑장 등 적당한 숙소 정보가 나온다. 주변에 물어보거나 검색해 적합한 제품이나 숙소를 찾고, 그 정보가 정확한지 확인할 필요도 없다. 함께 제공된 사이트 정보에 접속해 결제까지 바로 가능하다. 앞으로는 포털 사이트의 검색창이라는 중간 단계도 건너뛸 수 있게 된다. 말만 하면 맥락까지 이해하는 AI가 속속 등장하고 있어서다. ○개인 전문 비서를 곁에 두는 미래16일 업계에 따르면 오픈AI는 지난 13일 사람처럼 보고 듣고 말하는 새로운 AI 모델 ‘GPT-4o’를 공개했다. 다음날 구글도 비슷한 성능의 ‘프로젝트 아스트라’를 선보였다. 데미스 허사비스 구글 딥마인드 최고경영자(CEO)는 “오랫동안 일상생활에서 도움이 될 수 있는 범용 AI 에이전트를 개발하고 싶었다”며 “휴대폰이나 안경과 같은 폼팩터(기기 형태)를 통해 전문 비서를 곁에 둘 수 있는 미래가 올 것”이라고 강조했다.업계에서는 듣는 귀와 말하는 입을 갖게 된 ‘AI 에이전트’가 텍스트 검색을 대체할 것이란 전망이 나온다. 지금까지는 이용자가 인터넷에서 장시간 정보를 검색하고 관련 사이트를 찾아 업무를 처리해야 했다. 네이버의 블로그, 카페 등에서 여행 정보를 얻고 야놀자에서 날짜와 비용을 따져 예약하는 식이었다. AI 에이전트의 시대엔 검색과 실행 주체가 AI로 바뀐다.글로벌 인터넷 검색 서비스 시장에서는 이미 AI 챗봇의 영향이 나타나고 있다. 구글의 글로벌 검색엔진 점유율은 지난달 90.91%로 작년 1월(92.90%)

-
3
"이 장난감들로 동화 만들어줘"…순식간에 토이스토리 한 편 뚝딱
“어린 공룡 렉스는 커다란 은색 원반이 스쿨버스 옆으로 떨어지자 놀라지 않을 수 없었어요.”15일(현지시간) 구글 연례 개발자 회의(I/O)에서 처음 공개된 ‘프로젝트 아스트라’ 체험 부스에서 인공지능(AI)이 창작 동화를 들려줬다. 프로젝트 아스트라는 구글의 최신 AI 모델인 제미나이를 기반으로 개발한 멀티모달 AI 어시스턴트다. 사람처럼 보고 듣고 말하면서 사용자를 도와준다. AI에 공룡 장난감, 원형 우주선, 스쿨버스 세 개의 장난감을 보여주고 “이들을 주인공으로 동화 이야기를 들려달라”고 말했다. 그러자 AI는 망설임 없이 이야기를 시작했다.행사 이틀째인 이날 참가자들은 미국 캘리포니아 마운틴뷰 본사 옆에 있는 쇼어라인 엠피시어터의 체험 부스에서 구글의 다양한 AI 모델을 체험했다. 특히 프로젝트 아스트라 부스에는 긴 줄이 늘어섰다.부스는 벽에 설치된 대형 스크린과 천장에서 아래 테이블을 비추는 카메라로 구성됐다. 화면에 보라색으로 고양이를 그리자 AI는 “예쁜 고양이를 그렸구나. 잘했어”라고 말했다. 발을 추가로 그리자 “고양이에게 손이 생겼어”라고 반응했다. 카메라에 말없이 휴대폰을 올려놓아 봤다. AI는 “스타일리시한 스마트폰”이라고 말했다. 다만 어떤 브랜드의 무슨 모델인지는 파악하지 못했다.프로젝트 아스트라는 이전 영상에 대한 기억력도 있었다. 동물 인형 세 개를 차례로 보여준 뒤 “첫 번째로 보여준 인형이 뭐였지”라고 묻자 “강아지”라고 답했다. 실제 동물이 아니라 인형이라는 점도 구별했다. 반응 속도도 자연스러운 대화가 가능한 수준이었다. 구글이 작년 말 출시한 차세대 대규모



!["버핏, 애플 팔고 '9조' 베팅한 곳이…" 6개월 만에 깜짝 공개 [대가들의 포트폴리오]](https://timg.hankyung.com/t/560x0/photo/202405/01.36729398.1.jpg)





![[단독] "1억이 7억 된다" 달콤한 유혹…교수도 넋놓고 당했다](https://timg.hankyung.com/t/560x0/photo/202405/01.36700558.3.jpg)

![최강창민 '늦바람' 들게 한 '벤자민 버튼'…"삶 아름답게 정의해드립니다" [종합]](https://timg.hankyung.com/t/560x0/photo/202405/ZA.36735186.3.jpg)