인간처럼 사고하는 '멀티 모달 AI'…주문대로 척척 그림 그려
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
인간이 사물을 받아들이는 방식처럼
시각·청각 등 여러 채널 통해
정보 동시에 받아들여서 학습·사고
오픈 AI가 만든 '달리(DALL-E2)'
이미지들 개체별로 나누고 이름 부여
위치와 색상, 어떤 동작하는지 이해
문장 입력하면 어떤 그림·사진으로
이해하는지 우리에게 보여줘
멀티 모달 AI 활성화되면
상황 정확히 인지해 더 명확한 판단
질병 조기진단·원격진료에 이용
테러범 이미지 분석해 실
예를 들면 우리가 태어나서 처음 ‘사과’를 먹어본 기억을 떠올려보세요. 사과라는 단어가 머리에 각인되기 전에 이미 사과를 맛보고, 그 생김새와 색깔, 크기, 그리고 시큼하면서도 달콤한 맛, 까끌거리면서도 매끈한 촉감을 알게 됩니다. 그리고 비슷한 모양의 청사과, 풋사과, 잘 익은 사과, 상하거나 멍든 사과까지 여러 종류의 사과를 알게 되고 나서는 그것을 묶어서 서너 살쯤 말을 배우게 되면, ‘사과(apple)’라는 형이상학적 개념으로 뇌에 통합해서 저장하게 되죠. 이런 인류의 특별한 능력과 지적인 재능은 다양한 감각과 기억 등을 통합하는 역량에서 온 것입니다.
인류는 이렇게 사과라는 개념을 이해하기 위해 시각과 미각, 촉각, 텍스트까지 여러 개념을 통합해서 인식했죠. 그렇다면 우리가 만드는 인공지능(AI)은 어떻게 사과라는 개념을 받아들일까요. 이왕이면 인간이 학습했던 방법으로 배워야 인간과 제대로 소통할 줄 아는 AI가 되겠죠.
그래서 등장한 것이 ‘멀티 모달리티(multi modality)’입니다. ‘모달리티’는 양식, 양상이라는 뜻인데요, 보통 어떤 형태로 나타나는 현상이나 그것을 받아들이는 방식을 말합니다. 10년 전 쯤에는 웹 개발자와 사용자 인터페이스(UI) 디자이너가 사용자에게 보이거나 입력하는 방식 등을 하나로 단순화하면 ‘유니 모달리티’, 마우스와 키보드, 화면과 음성 등 여러 채널을 이용하면 ‘멀티 모달리티(멀티 모달)’라고 불렀던 시절이 있었습니다.
지금의 ‘멀티 모달’은 시각, 청각을 비롯한 여러 인터페이스를 통해 정보를 주고받는 것을 말하는 개념입니다. 이렇게 다양한 채널의 모달리티를 동시에 받아들여서 학습하고 사고하는 AI를 ‘멀티 모달 AI’라고 합니다. 쉽게 말하면 인간이 사물을 받아들이는 다양한 방식과 동일하게 학습하는 AI라고 볼 수 있겠네요.
기존에 우리가 개발한 AI는 텍스트나 자연어를 이해하는 데 중점을 뒀습니다. 인류가 만든 가장 많은 데이터는 글로 남겨진 텍스트였고, 사람이 주고받는 언어를 이해하는 자연어 분석(NLP)이 전제돼야 명제와 추론을 할 수 있다고 본 거죠. 우선은 사람이 하는 질문을 이해해야 답을 내놓을 수 있기도 했고요.
그런데 여기서 문제가 발생합니다. AI는 실제 그 단어가 의미하는 것이 어떻게 생겼고, 실제 세상에 어떤 형태로 존재하는지 이해하지 못하는 겁니다. 예를 들어 ‘남자가 말을 타고 있다’라는 문장에서 ‘탄다(ride)’라는 개념을 이해하지 못하고, 말의 크기가 얼마만 한 것인지, 어떤 형태로 타는 것인지 알 수가 없죠. 즉 데이터 처리나 통계, 텍스트를 검색해서 보여주는 것은 가능하지만, 인간과 비슷한 방식의 사고는 할 수가 없습니다. AI가 우리 세상을 제대로 인식할 수 있도록 하려면 멀티모달 AI의 등장은 필수적이었다고 봐야겠죠.
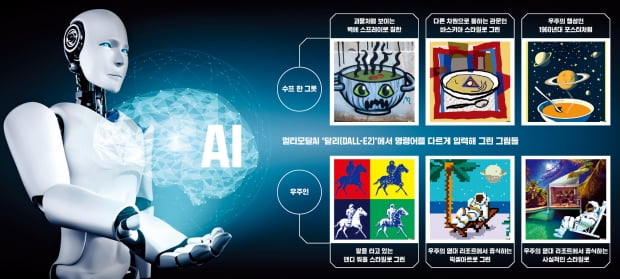
우리에게 가장 많이 알려진 멀티 모달 AI는 오픈AI가 만든 ‘달리(DALL-E2)’입니다. 오픈AI는 ‘AI 시스템이 우리 인류를 어떻게 보고 이해하는지 도움이 되도록 하고자’ 멀티 모달 AI를 활용해 만들었다고 밝혔습니다. 달리는 문장을 입력하면, 해당 문장이 어떤 형태의 그림과 사진으로 이해되는지를 보여줍니다. 즉 우리가 입력한 문장을 달리는 ‘저는 이렇게 이해하고 있어요’라고 보여주는데요. 달리는 기존 이미지들을 개체별로 나누고 이름을 부여한 다음 위치와 색상, 어떤 동작을 하고 있는지를 이해합니다. 그리고 이미지를 설명하는 데 이용된 텍스트 간의 관계를 학습하죠.
폭력·혐오·성인용 이미지는 학습 대상서 제외…
AI로 나쁜 결과물 만들어내는 부작용 차단

그러고 나서 달리에게 ‘우주에서 고양이와 농구하는 것’을 그림으로 만들어 달라고 하면 오른쪽 위 사진과 같이 해줍니다. 한 가지 과정을 빠뜨렸네요. 달리는 인상파 화가 모네 스타일로, 앤디 워홀 스타일로, 어린이 동화 일러스트 스타일로 해달라고 하면 그런 페인팅 기법도 이해하고 만들어 줍니다.
국내에서는 LG AI 연구원에서 텍스트를 이미지로 만들어주는 ‘엑사원’을 발표했는데요. 엑사원은 이미지를 텍스트로 설명해주는 것도 가능한 양방향 멀티 모달 AI라고 해요. 그리고 인텔과 카네기멜론대가 손잡고 개발한 ‘WebQA’는 웹상의 데이터와 이미지를 학습한 다음 사용자 질문에 답을 찾아주는 서비스입니다. 예를 들면 특정 새의 눈 주변 원 모양은 무슨 색상인지 물어보면 빨간색이라고 답을 알려주죠.
지금까지는 이미지를 만들어 내고 검색하는 정도로만 활용되는 단계인데요. 텍스트와 이미지, 개체 간의 관계를 통해 AI가 학습하는 ‘확산(diffusion) 모델’을 사용해서 지식을 축적하는 단계라고 보면 될 것 같습니다.
멀티 모달 AI가 활성화되면 텍스트나 이미지로만 가능했던 활용 영역을 엄청나게 변화시킬 겁니다. 앞에서 예로 들었던 챗봇 AI는 단순하게 고객이 말하는 자연어를 분석해, ‘이 정보를 찾아달라고 하는구나’를 목적으로 하는 게 대부분이죠. 멀티 모달 AI라면 ‘번호판이 3X가1234인 차량의 전면부가 크게 파손된 사진’만 보험사에 전송하면, 해당 차량이 가입된 보험 상품을 검색하고, 고객의 피해 정도가 얼마나 될지 예측한 다음 담당자와 고객에게 사고 접수와 처리를 바로 진행하도록 해줄 수 있습니다. 즉 정확한 상황 인지를 통해 조금 더 명확한 판단을 내릴 수 있는 똑똑한 AI가 되는 거죠.
첩보영화에서나 보던 테러범의 이미지를 분석해 폐쇄회로TV(CCTV)에서 실시간으로 찾아내는 상상 속의 이야기가 현실이 될 것입니다. 자동차업계에서는 자율주행에서 필수적인 속도, 차선 위반, 운전자 상태, 날씨까지 여러 정보를 기반으로 하는 AI도 멀티 모달 기반으로 구현돼야 할 테고요. 의료계에서도 사람의 눈으로 알아낼 수 없는 질병의 초기 진단 및 원격 진료에서 크게 활약할 것으로 예상하고 있어요. 멀티 모달 AI는 사람과 동일한 방식으로 세상을 인지하지만, 더욱 날카롭고 정확하게 분석해 낼 수 있을 테니까요.
하지만 멀티 모달 AI에 대해 우려가 없는 건 아닙니다. 모든 AI의 가장 큰 위험 요소는 ‘딥페이크’ 같은 AI 기반으로 만들어진 가짜가 범죄에 활용되거나, 편향되거나 폭력적인 이미지와 텍스트 등을 기반으로 학습돼 나쁜 결과물을 만들어내는 것입니다. 그래서 달리에서는 폭력과 혐오, 성인용 이미지는 학습 대상에서 제거하고, 공적인 인물을 포함해 실제 개인의 얼굴을 보여주지 않습니다. 달리의 결과물을 보면 사람 얼굴이 조금 이상하게 표현되는 것은 그런 이유 때문이죠. AI의 미래는 사람과 동일한 책임이 따르도록 규제하는 것이 필요한 시대가 되었습니다. 여러분도 달리에게 재미난 그림을 그려달라고 해보세요!
배성수 기자/도움=삼성SDS

ADVERTISEMENT
-
1
네이버, 카카오, KT 등 국내 주요 정보기술(IT) 기업이 물류 사업을 강화하고 있다. 물류산업이 빠르게 성장하는 가운데 IT를 활용한 디지털 전환(DX) 수요가 높다는 점이 배경으로 손꼽힌다. 국토교통부에 따르면...

-
2
아티스트와 팬들 쌍방향 소통…급성장한 팬덤 플랫폼 '위버스'
“팬 활동을 좀 더 쉽게 할 수는 없을까.”‘팬질·덕질’에도 애로사항이 있다. 모든 팬은 아티스트의 활동을 한곳에서 쉽게 찾아보기를 원한다. 내가 좋아하는 그 ...
-
3
의료 현장도 '디지털 전환'…원격 임상시험 시대 빨라지나
각 산업에 디지털 전환 바람이 불고 있다. 임상시험 분야 또한 정보기술(IT)과 만나면서 분산형 임상시험(Decentralized Clinical Trials·DCT) 시대로 새로운 전환기를 맞고 있다....

ADVERTISEMENT

![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


