매일 아침 쌓인 카톡 300개 요약…"너무 편리한데 섬뜩"
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
AI 요약 앱 이용자 수 급성장
일각에선 개인 정보 유출 우려도
카카오 "기술 메커니즘 상 불가능"
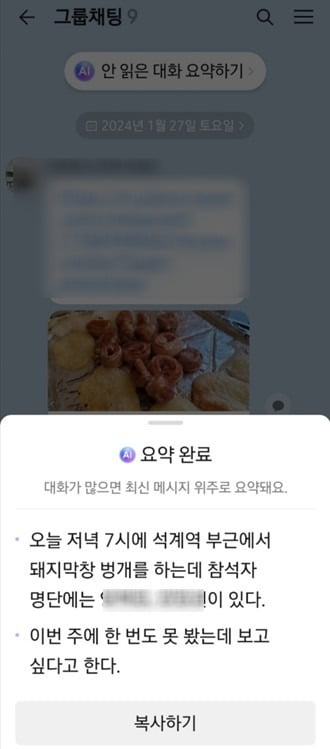
20대 직장인 고모 씨는 "카톡 대화 요약 기능이 나온 이후 매일 쓰고 있다"며 "생뚱맞게 요약할 때도 있지만 대체로 행간 파악을 잘해서 놀랄 때가 많다"며 이같이 말했다.
최근 인공지능(AI) 기술이 발전하면서 주요 IT 기업이 출시한 AI 애플리케이션(앱) 서비스들이 인기를 끌고 있다. 특히 2030 직장인 사이에서 "일상·업무용으로 요긴하다"는 평을 얻고 있는 기능이 이 'AI 요약' 기능이다. 카카오톡의 '안 읽은 대화 요약하기', 네이버 클로바노트의 '음성 기록 메모·요약' 기능, SK텔레콤 에이닷의 '통화요약'이 대표적이다.
출시한 지 6개월 남짓인 서비스들이지만 실생활에 빠른 속도로 정착하고 있다. 지난달 16일 아이지에이웍스 마케팅클라우드가 발표한 2023년 AI 앱 트렌드 리포트에 따르면 SK텔레콤의 AI 앱 '에이닷'의 월간 활성 이용자 수(MAU)가 시범 서비스 운영 기간인 지난해 1월 약 37만명에서 12월에는 이용자 수 약 125만7000명까지 성장했다. 같은 해 9월 통화 녹음, 요약 기능을 추가해 정식 서비스를 출시해서다. 1년 새 이용자 수가 3.5배 가까이 늘면서, 지난해 가장 급격한 성장을 보인 AI 앱으로 등극했다.
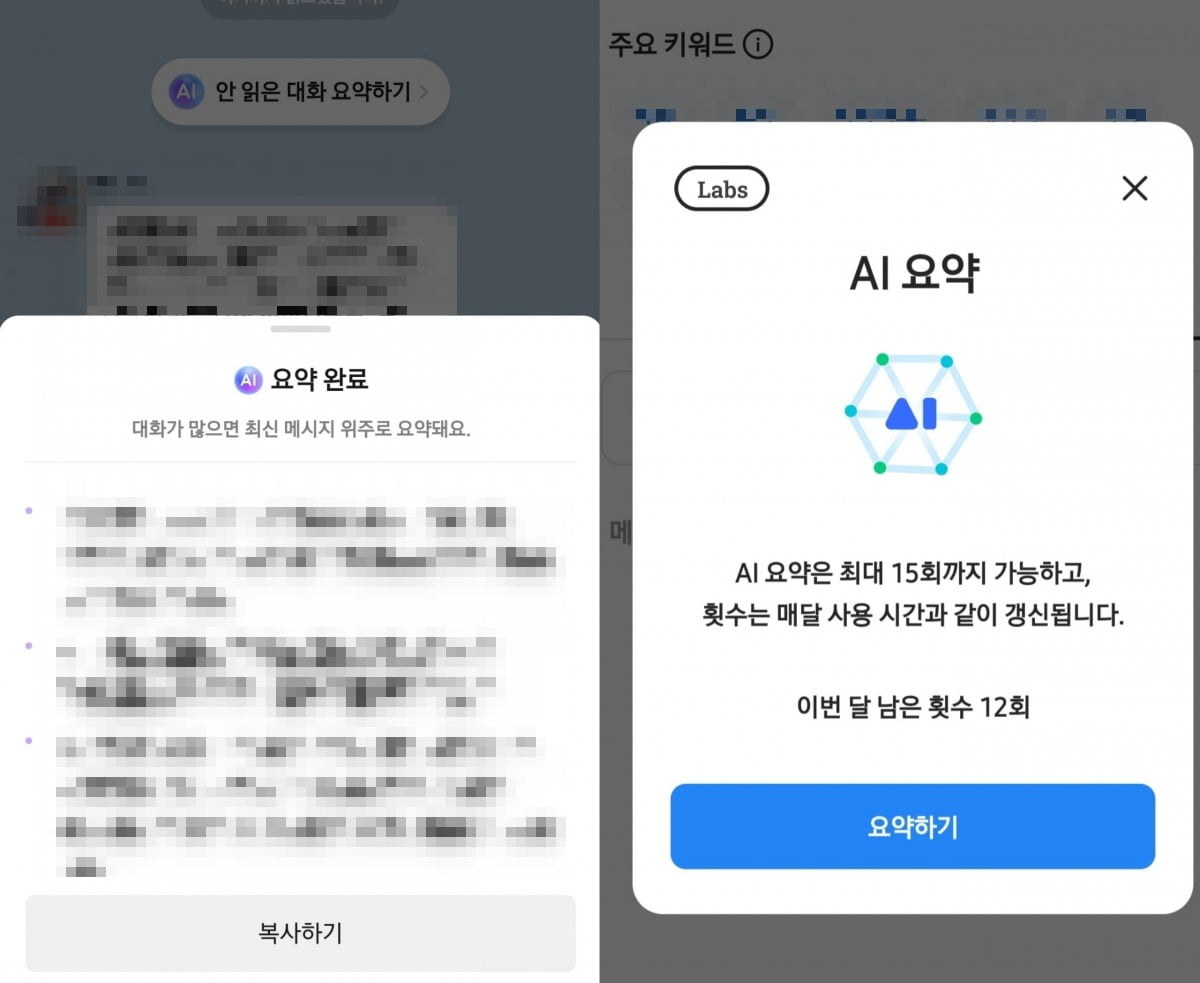
이러한 서비스들은 모두 각 기업이 개발한 거대 언어 모델(LLM)을 기반으로 한다. 이용자의 대화 내용을 텍스트로 먼저 바꾼 뒤 언어 모델에 입력하면, 모델이 알아서 요약문을 도출하는 구조다.
대체로 일상생활에 도움이 된다는 의견이 많지만, 빠르게 스며든 만큼 우려도 적지 않다.
3개월째 에이닷의 '통화요약' 기능을 사용하고 있다는 대기업 인사팀 직원 20대 이모 씨는 "AI 요약 기능이 이렇게 정확해진 것이 놀랍다"며 "한편으론 이렇게 기술이 고도화되기까지 분명 많은 양의 학습 데이터가 필요했을 텐데, 기능을 사용하는 지금 이 순간도 내 개인 정보가 유출되고 있는 건 아닌지 섬뜩할 때가 있다"고 털어놨다.
한 직장인 익명 커뮤니티에 "카톡 AI 요약 서비스를 사용하는데 톡방에서 말하지 않은 아예 외적인 내용도 요약에 반영될 때가 있다"며 "타인의 금융정보 같은 것도 요약해주면 어떡하냐. 긴급 점검해야 할 것 같다"는 주장이 올라오기도 했다.

'대화방 외부 내용이 요약에 포함됐다'는 CS가 접수된 적도 없는 것으로 확인됐다.
네이버 클로바노트 관계자도 "이용자의 동의 없이는 AI 언어 모델 학습에 데이터를 활용할 수 없다"며 "환경 설정에 들어가 별도의 동의 처리를 하는 사용자에 한해 학습용 데이터를 취합하고 있다"고 밝혔다.
전문가들 또한 "이미 완성된 서비스에 내용만 입력하는 구조라 기술적으로 개인 정보가 유출될 우려는 없다"고 했지만 일각에선 여전히 의심의 눈초리를 보내고 있다.
서정연 서강대 컴퓨터공학과 연구석학교수는 앱별 AI 요약 기능에 대해 "요약 수준의 AI 기술은 이미 추가적인 언어 모델 훈련 없이도 고품질의 결괏값을 도출해낼 수 있는 영역"이라면서 "되레 정제되지 않은 이용자 데이터를 학습에 활용했을 때 언어 모델의 정확도가 떨어지고 오류가 발생하는 등의 문제가 발생할 수 있다"고 설명했다.
그는 "요즘에는 업계서도 윤리 의식이 많이 향상된 상황이라 대부분 훈련 데이터를 구입하거나 자체적으로 개발한다. 굳이 이용자 데이터까지 무단으로 수집할 이유가 없다"고 설명했다.
한 업계 관계자는 "기술적으로 이미 개발을 마친 언어 모델의 경우 업데이트를 할 때가 아니라면 추가적인 데이터가 더 필요하지 않은 건 맞다"면서도 "다만 최근 인기를 끌고 있는 서비스들이 모두 시범 단계라 추후 서비스 보완을 할 때는 정보 활용에 동의한 이용자에 한해서 데이터를 수집할 것으로 보인다"고 부연했다.
반면 익명을 요구한 한 대학의 컴퓨터공학과 교수는 "사실상 AI 언어 모델 개발이라는 것 자체가 연구자의 선의에 기대는 부분이 많다"며 "언어 모델 훈련에 필요한 코퍼스(corpus·말뭉치) 데이터들을 확보하는 과정에 대한 이렇다 할 가이드라인이 없어 모호한 지점이 많은 상황"이라고 지적했다.
김영리 한경닷컴 기자 smartkim@hankyung.com

ADVERTISEMENT

-
1
주식창이 '빨간불'로 반짝반짝…시총 상위주 '즐거운 비명'
시가총액 상위 종목들이 일제히 빨간불을 켰다.2일 오전 9시28분 현재 코스피지수는 전장 대비 33.35포인트(1.31%) 오른 2575.81에 거래 중이다. 유가증권시장 시총 상위 10종목들을 살펴보면 대장주인 삼...

-
2
네이버 연매출 9조 돌파…커머스·콘텐츠가 이끈 '최고 실적' [종합]
네이버가 지난해 커머스와 콘텐츠 고성장으로 연매출 9조원을 돌파했다. 네이버는 지난해 매출 9조6706억원으로 전년(2022년) 대비 17.6% 늘었고 영업이익은 1조4888억원으로 같은 기간 14.1% 증...
![네이버 연매출 9조 돌파…커머스·콘텐츠가 이끈 '최고 실적' [종합]](https://img.hankyung.com/photo/202402/01.35609896.3.jpg)
-
3
지난해 연간 최대 실적을 거둔 네이버의 주가가 오르고 있다.2일 오전 9시 9분 기준 네이버는 전일 대비 9500원(4.69%) 오른 21만2000원에 거래되고 있다. 주가는 장 초반 21만3000원까지 오르기도 했...

ADVERTISEMENT

![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


