KAIST, 최적의 인공지능 딥러닝 데이터 선택 기술 개발
딥러닝은 훈련 데이터로부터 반복적으로 일부 데이터 샘플을 선정해 최적화하는 과정으로 이뤄진다.
이때 선정된 데이터 샘플을 '배치'(batch)라고 부른다.
배치를 무작위로 선택할 경우 정확도가 떨어지기 때문에 학습에 적합한 데이터를 골라내기 위한 연구가 활발히 진행되고 있다.
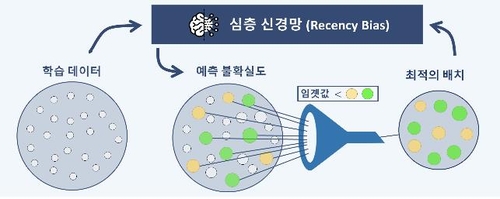
연구팀은 데이터 추론 결과를 활용해 현재 모델 학습 단계에 가장 도움이 되는 데이터를 효과적으로 선택할 수 있는 기술을 개발했다.
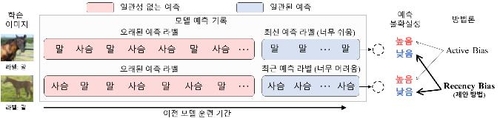
단계별 추론 단계에서 데이터가 너무 쉬우면 답을 계속 맞히거나, 반대로 너무 어려우면 계속해서 틀리게 되는 일관적인 결과가 나타난다.
이 같은 데이터는 예측 정확도를 높이는 데 도움이 되지 않는다.
반대로 몇 단계에서의 추론 결과가 일관적이지 않다면 데이터 추론이 혼동되고 있다는 뜻으로, 현재 시점에서 난도가 적절한 데이터라고 볼 수 있다.
연구팀은 이 같은 방법론을 '최신 편향'(Recency Bias)이라 이름 붙이고 이를 시각적 이미지를 분석하는 데 사용되는 인공신경망의 한 종류인 '합성 곱 신경망'(Convolutional Neural Network) 학습에 적용했다.
이번 연구 결과는 데이터 처리 분야 국제 학술대회 '국제컴퓨터학회 정보지식관리 콘퍼런스 2020'(ACM CIKM)에서 23일 발표된다.
/연합뉴스
-
기사 스크랩
-
공유
-
프린트
-
1
"어도어 빈껍데기로 만든다" 치밀한 계획…하이브, 결국 고발
하이브가 자회사 어도어 경영진들에 대한 중간 감사 결과를 공개하며 이들을 업무상 배임 등의 혐의로 고발한다고 밝혔다.25일 하이브가 발표한 감사 결과에 따르면 하이브는 어도어 대표이사 주도로 경영권 탈취 계획이 수립됐다는 구체적인 사실을 확인하고 물증도 확보했다.감사대상자 중 한 명은 조사 과정에서 경영권 탈취 계획, 외부 투자자 접촉 사실이 담긴 정보자산을 증거로 제출하고 이를 위해 하이브 공격용 문건을 작성한 사실도 인정했다.대면 조사와 제출된 정보자산 속 대화록 등에 따르면 어도어 대표이사는 경영진들에게 하이브가 보유한 어도어 지분을 매각하도록 하이브를 압박할 방법을 마련하라고 지시했다.이 지시에 따라 아티스트와의 전속 계약을 중도 해지하는 방법, 어도어 대표이사와 하이브 간 계약을 무효화하는 방법 등이 구체적으로 논의됐다. 또한 '글로벌 자금을 당겨와서 하이브랑 딜하자', '하이브가 하는 모든 것에 대해 크리티컬하게 어필하라', '하이브를 괴롭힐 방법을 생각하라'는 대화도 오갔다.대화록에는 '5월 여론전 준비', '어도어를 빈 껍데기로 만들어서 데리고 나간다'와 같은 실행 계획도 담겼다.하이브는 감사대상자로부터 "'궁극적으로 하이브를 빠져나간다'는 워딩은 어도어 대표이사가 한 말을 받아 적은 것"이라는 진술도 확보했다.하이브는 해당 자료들을 근거로 관련자들에 대해 업무상 배임 등의 혐의로 25일 고발장을 제출할 예정이다.아울러 뉴진스 멤버들에 대한 심리적, 정서적 케어와 성공적인 컴백을 위해 최선을 다해 지원할 계획이다. 또한 멤버들의 법정대리인과 조속히 만나 멤버들을 보

-
2
鳥居토리이신사 입구의 기둥문 娘 : お父さん、大きな門だね。무스메 오 토- 상 오- 키 나 몬 다 네父 : はははは。鳥居っていうんだよ。치치 하 하 하 하 토리 잇 떼 이 운 다 요 立派な大木だろう。樹齢800年だって。 립 빠 나 타이보쿠 다 로- 쥬 레- 합 뺘쿠 넨 닷 떼娘 : 樹齢?무스메 쥬 레-父 : 木の年齢のこと。800歳ってことだな、この木の歳は。치치 키 노 넨 레- 노 코 토 합 뺘쿠 사 잇 떼 토 코 다 나 코 노 키 노 토시 와 딸 : 아빠~ 큰 문이네.아빠 : 하하하하. 토리이라는 거야. 좋은 거목이지? 수령이 800년이래. 딸 : 수령?아빠 : 나무의 나이야. 이 나무 나이가 800살이라는 거지. 鳥居(とりい) : 신사 입구에 세워 둔 기둥문立(りっ)派(ぱ) : 훌륭함大(たい)木(ぼく) : 거목, 큰 나무樹齢(じゅれい) : 수령, 나이의 나이
-
3
의대 교수들마저 병원을 떠날지 이목이 쏠리고 있다.의료계에 따르면 25일 '빅5' 병원을 포함한 전국 의대 교수들은 병원과 진료과별 사정에 따라 이날부터 사직을 시작한다. 이는 지난달 25일 의대 교수들이 의대 정원 확대 등 정부의 의료 개혁에 반대해 사직서를 제출한 것에 따른 것. 민법상 1개월이 지나면 사직서의 효력이 발생한다고 보고 있다.전국의과 대학교수 비상대책위원회(전의비)는 지난 23일 온라인 총회 후 "예정대로 4월 25일부터 사직이 시작된다는 것을 재확인했다"며 "정부의 사직서 수리 정책과 관계없이 진행하겠다"고 전했다. 전의비에는 전국 20여개 의대가 참여하고 있다.서울대 의대·서울대병원 교수협의회 비상대책 위원도 "교수들이 사직서를 제출한 날로부터 30일이 지난 시점부터 개인의 선택에 따라 사직을 실행한다"며 "비대위 수뇌부 4명은 5월 1일부터 실질적으로 병원을 떠난다"고 밝혔다. 서울대 의대교수 비대위에는 서울대병원, 분당서울대병원, 서울시보라매병원, 서울대병원 강남센터 등 4개 병원 교수들이 속해 있다.울산의대 교수협의회 비상대책위원회는 진료와 수술 예약 상황을 고려해 25일부터 사직을 진행하겠다고 밝히면서, 당장 사직하지 못하는 교수들은 5월 3일부터 주 1회 휴진할 예정이라고 안내했다. 울산의대는 서울아산병원을 비롯해 울산대 의대·강릉아산병원 등을 수련병원으로 두고 있다.세브란스병원·강남세브란스병원·용인세브란스병원 등을 수련병원으로 두고 있는 연세대 의대교수 비상대책위원회는 전날 서울 서대문구 연세의대 윤인배홀·강남세브란스병원 대강당·용인세브란



!['매그니피센트7' 실적 먹구름…지수 혼조 [뉴욕증시 브리핑]](https://timg.hankyung.com/t/560x0/photo/202404/01.36519299.1.jpg)








![AI에게 이렇게 말해보세요 "심호흡 한번 하고 문제를 해결해보자" [WSJ 서평]](https://timg.hankyung.com/t/560x0/photo/202404/01.36512304.3.jpg)