"21세기판 인형 눈붙이기"…'한국판 뉴딜 일자리' 체험해보니

문재인 정부는 지난 14일 신산업 분야에 160조원을 투자해 190만개의 일자리를 만든다는 '한국판 뉴딜 종합계획'을 발표했다. 이 중 정부가 내세운 대표적인 간판 사업이 '데이터 댐' 구축이다. 수많은 데이터를 수집하고 정리해 데이터 산업 발전의 발판으로 삼겠다는 계획이다. 데이터 수집 및 가공을 뜻하는 '데이터 라벨링'은 취업난을 겪는 청년들에게 주로 맡기기로 했다. 정부는 이로 인해 창출되는 일자리가 10만개에 이를 것으로 예상했다.
하지만 전문가들은 "정부 주도의 데이터 라벨링은 막대한 예산만 낭비하고 실제 산업에서 쓸 수 없는 데이터만 양산할 가능성이 높다"고 우려하고 있다. 정책 목표가 신산업 발전이 아닌 '단기 일자리 제공'에 매몰되면서, IT업계에서 통용되는 '가비지 인, 가비지 아웃(garbage in, garbage out)'이라는 말처럼 질 낮은 데이터만 대량으로 양산될 수 있다는 우려다. 데이터 라벨링이 무엇이고, 실제로 관련 일자리는 어떤 모습인지 직접 체험해 정리했다.
'데이터경제 핵심' 데이터 라벨링이 뭐길래
데이터 라벨링은 디지털 데이터에 ‘라벨’을 붙이는 작업이다. 과학기술정보통신부는 ‘기술·산업적으로 유망하고 AI응용개발에 공통적으로 활용 가능한 이미지·영상 등 범용성 높은 인공지능(AI) 데이터를 구축하는 것’으로 정의하고 있다. 이렇게 구축한 데이터는 인공지능(AI)이 학습하는 '교과서'로 쓰인다.예컨대 개의 사진을 보고 견종이 무엇인지 판별해 주는 서비스를 개발한다고 하자. 전문가들은 개의 사진을 보면 견종을 높은 정확도로 빠르게 파악할 수 있다. 하지만 AI에게는 사사진의 어떤 부분이 '개'에 해당하는지조차 정확하게 파악하기 어렵다. 사람이 하나하나 가르쳐 줄수도 없다. 빛과 주변 환경, 강아지의 모양 등에 따라 수없이 많은 경우의 수가 존재해서다.
자동학습 AI는 이런 문제를 해결할 수 있다. '학습 데이터셋'을 통해서다. 예컨대 수십만 건의 개 사진과, 개가 사진의 어느 부분에 있고 어떤 종류인지 판별해 정리한 데이터를 AI에게 쥐어 준다. AI는 먹지도 자지도 않고 빠르게 이를 학습해 사진에서 '개'를 집어내고 견종을 정확하게 판별해내는 확률을 높인다. '알파고'가 세계 최정상급의 바둑 실력을 갖추게 된 것도 비슷한 과정을 통해 이뤄졌다.
데이터셋이 많을수록, 즉 공부량이 많을 수록 AI가 실수할 확률은 낮아진다. 질 높은 데이터를 많이 공부한 AI일수록 서비스의 질이 높다는 얘기다. 데이터 산업 경쟁력을 높이려는 정부가 일반 사업자들이 활용할 수 있는 데이터를 대량으로 양산하려는 이유도 여기에 있다.
‘데이터 라벨러’ 돼보니…“인형 눈 붙이기와 비슷”
'데이터 라벨링' 일자리를 직접 체험해 봤다. 이미 민간에는 몇 개의 '데이터 라벨링 플랫폼' 업체가 있다. IT기업 등 AI 학습용 데이터를 필요로 하는 업체와 아르바이트생을 이어주고 소정의 수수료를 떼어 가는 기업들이다. 기자는 이 중 한 업체에 가입해 교육용 서비스를 체험했다. 올라온 일거리에 지원해 업무를 수행한 뒤, 업무를 제대로 수행했는 지 검사를 받아 통과되면 건당 20원에서 200원 상당의 포인트를 지급받을 수 있다. 포인트가 일정액(1000원) 이상이 되면 이를 현금화할 수 있다.건당 20원을 지급하는 '텍스트 태깅'은 간단한 언어 능력 테스트와 비슷했다. 예컨대 보고서의 일부 내용을 주고 이 중 필요한 팩트를 추려 마우스로 지정하는 방식이다. 약관이나 법조문 등 내용이 길고 가독성이 낮은 문서의 핵심을 추려서 보여주는 AI서비스 등에 활용이 가능할 것으로 보인다. 난이도는 쉬웠지만 건마다 '정답'의 기준이 다른 점은 주의가 필요했다. 예컨대 지문에서 요구하는 답으로 '데이터 인프라부문'이라는 응답은 반려되고, 반드시 '데이터 인프라'라고만 답해야 하는 식이었다.
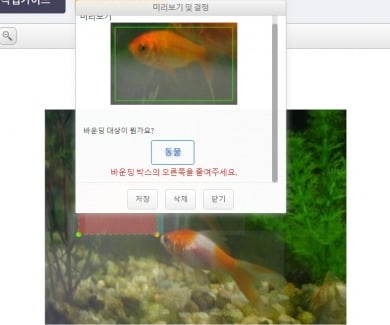

한 시간 가량 작업들을 완료한 뒤 기자가 번 돈은 3000원 수준. 처음 해 보는 작업이라 숙련도가 현격히 낮다는 점을 고려할 때, 익숙해지면 최저임금 정도의 돈은 벌 수 있을 것으로 예상된다. 상당한 집중력이 필요한 업무면서도 시간과 공간에 얽매이지 않고 할 수 있다는 점도 매력적이었다.
하지만 정부 관계자들이 말하는 "업무 경험을 쌓을 수 있는 일자리"와는 거리가 멀어 보였다. 육아 휴직을 하면서 해당 플랫폼을 통해 이때까지 100만원 안팎의 돈을 벌었다는 박모씨(31)는 “건당 돈을 받고 엄격한 사후 감독을 받는다는 점에서 영화 ‘기생충’에 나온 피자곽 접는 업무와 비슷하다”며 “개인적으로는 돈을 벌 수 있어 만족하지만 커리어나 직무 능력 개발에 도움은 전혀 안 된다”고 평가했다.
"취지는 좋지만 정부 주도는 안돼"
정부는 이 같은 일자리를 앞으로 10만개 만들어 청년에게 공급할 계획이다. 이미 행정안전부와 과기부 등은 연내 1000억원 가량을 들여 데이터 라벨링 인턴 및 전문 일자리를 1만개 만들겠다고 밝혔다. 대부분은 4개월짜리 '단기 알바'다. 신종 코로나바이러스 감염증(코로나19)으로 인한 청년들의 어려움을 완충하려는 '공공 근로' 성격이 크다.문제는 이렇게 만들어진 데이터들이 쓸모 없을 가능성이 높다는 점이다. 먼저 데이터의 품질 문제가 지적된다. 기자가 체험한 업체 등 민간 플랫폼들은 건마다 까다로운 심사를 거쳐 작업료를 지불하고 있다. "심사가 너무 느리고 까다롭다"는 불만이 많을 정도다. 이는 자동학습 AI의 성능을 높이려면 데이터의 '질'이 그만큼 중요해서다. 질 낮은 데이터, 즉 배웠던 것과 전혀 다른 거짓말투성이 데이터를 자동학습 AI가 봤다가는 성능이 오히려 저하될 수 있다. 기존에 공부한 것도 모르게 된다는 얘기다.
하지만 정부의 데이터 라벨링 일자리는 공공근로 성격이 강해 건수가 아닌 시급으로 임금을 지급한다. 극단적으로 말해 한 시간 내내 틀린 데이터셋 한두 개만 만들어도 월 200만원 가량을 받을 수 있다는 얘기다. 일을 집중해서 해야 할 유인이 그만큼 떨어지고, 만든 데이터의 신뢰성도 의심받을 수 밖에 없다.
수요자가 원하는 정보가 아닌 '공급자 위주'의 데이터 공급이라는 점도 문제로 지적된다. 자율주행차나 스마트시티 등 일단 데이터를 이용할 목적과 사업 계획이 뚜렷해야 실제 산업에서 사용이 가능한 AI 학습용 데이터를 만들 수 있다는 게 전문가들의 지적이다. 국책연구기관의 한 관계자는 “일단 데이터부터 만든 다음에 사용처를 고민해보자는 것은 '벽돌을 들판에 던져놓으면 빌딩이 된다'는 것과 다름이 없다”며 “집을 지을 때 설계를 한 뒤 맞는 재료를 만들어 공급하듯이 데이터도 맞춤형으로 만들지 않으면 '정크 데이터'가 될 것”이라고 지적했다.
이런 문제점들은 데이터를 '정부 주도'로 구축하려는 시도에서 비롯됐다는 분석이 나온다. 해외 IT 기업들은 개발도상국 근로자 등에 데이터 라벨링 작업을 맡기고 있다. 언어와 관련 없는 작업이라면 부담없이 맡길 수 있는 데다 임금도 시간당 2달러 정도에 불과하다. 자동학습 AI가 사용할 데이터조차도 또다른 자동학습 AI로 만들기 위한 시도도 계속 이뤄지고 있다. 데이터 라벨링 관련 민간 산업이 한국에서는 이제 기지개를 막 켜는 수준인데, 정부의 개입으로 발전이 저해될 것이라는 우려도 있다.
정부 관계자는 "디지털 뉴딜은 아직 큰 윤곽이 제시된 것이고, 단기 일자리를 만드는 것은 코로나19 극복을 위한 경기 대응 성격도 크다"며 "업계에서 제기되는 문제점을 주의깊게 듣고 있으며 향후 발표할 추가 계획 등에 이를 반영해 보완해 나가겠다"고 말했다.
성수영 기자 syoung@hankyung.com
-
기사 스크랩
-
공유
-
프린트
-
1
삼성, 차세대 스마트폰 가격 낮추고 출시 일정 앞당긴다
삼성전자가 올 하반기 주력 스마트폰 신제품들의 개통일을 지난해보다 앞당기고 가격도 내릴 것으로 전망된다. 코로나19(신종 코로나바이러스 감염증) 사태로 스마트폰 사업이 지지부진하자 수요를 늘리기 위한 대응책으로 풀이된다.25일 업계에 따르면 삼성전자는 다음 달 5일 신제품 공개 행사인 '갤럭시 언팩'을 코로나19 여파에 사상 처음으로 온라인으로 개최하고 5종의 신제품을 선보인다.프리미엄 스마트폰 '갤럭시노트20' 시리즈와 폴더블폰 '갤럭시 Z 폴드2', 스마트 워치 '갤럭시 워치3', 무선 이어폰 '갤럭시 버즈 라이브', 태블릿 '갤럭시 탭 S7' 등이 공개될 것으로 예상된다.이동통신업계에 따르면 갤럭시 노트20 시리즈의 사전예약은 다음 달 7일부터 13일까지다. 사전 개통은 같은 달 14일부터 20일까지이며 본 개통은 21일부터 진행된다. 이는 예년보다 일주일가량 빠른 것이다. 지난해 '갤럭시노트10' 시리즈는 8월20일에 사전 개통을 진행한 뒤 23일 정식 출시됐다. '갤럭시노트9'는 2018년 8월21일 사전개통 후 24일 본개통이 진행됐다.사전예약과 개통을 앞당기는 것은 신제품 판매기간을 최대한 늘리고 경쟁제품 혹은 자사 다른 제품과의 '집안싸움'을 막아 수요를 극대화 하겠다는 전략으로 풀이된다. 가격도 인하한다. 갤럭시노트20 일반 모델은 119만9000원으로 전작(124만8500원)보다 5만원가량 싸졌다. 삼성전자가 내놓는 프리미엄 5세대 통신(5G) 스마트폰 중 가장 저렴한 가격이다. 상위 모델인 갤럭시노트20 울트라는 145만2000원으로 책정됐다.삼성전자는 최근 국내에 출시하는 프리미엄 스마트폰의 출고가를 계속해서 올리는 추세였지만, 코로나19 여파 등으로 소비 심리가 타격을 받자 5G 도입 이후 처음으로 주력 스마트폰의 가격을 전작 대비 낮췄다.차세대 폴더블폰의 경우에도 국내 출시 일정이 당초 예상보다 빠를 것으로 보인다. 삼성전자가 언팩에 앞서 공개한 '갤럭시 Z 플립 5G'와 갤럭시 Z 폴드2는 오는 9월18일 국내에 출격할 것으로 예상된다. 갤럭시노트20 출시일보다 한 달 가량 늦게 출시하는 이유는 갤럭시노트20과 구매층이 겹쳐 시장을 '잡아먹는' 현상을 막기 위해서로 해석된다.갤럭시폴드는 지난해 9월16일부터 한정 판매 형식으로 출시된 이후 다음 달인 10월21일 삼성전자 홈페이지와 전국 삼성 디지털 프라자, 모바일 스토어, 이동통신사 매장 등에서 일반 판매를 진행했다.폴더블폰 2종은 아직 구체적인 가격이 발표되지 않았다. 다만 갤럭시 Z 폴드2는 230만원대로 239만8000원이었던 전작보다 가격을 소폭 낮추는 안을 논의 중인 것으로 알려졌다.배성수 한경닷컴 기자 baebae@hankyung.com
-
2
中 영어 강사가 키운 기업…9년 만에 시총 240조 '껑충' [조아라의 소프트 차이나]
수학 점수 '1점'. 1982년 첫 가오카오(중국 수능)을 치른 한 소년의 손에는 초라한 성적표가 들려있었습니다. 야심만큼은 누구보다도 컸던 이 소년은 중국 최고 명문대학인 베이징대에 지원해 보기 좋게 낙방했습니다. 이듬해 다시 치른 시험에서 수학 점수는 고작 19점. 이후 세번째로 본 시험에서 79점을 받고 1984년 정원 미달로 간신히 항저우사범대 외국어과에 입학하게 됩니다.영어 강사로 활동할 만큼 언어에 특기가 있던 그는 미국 출장길에 오르면서 일생일대의 전기를 맞이하게 되는데요. 우연히 인터넷에 'beer(맥주)'를 검색했는데, 미국·독일 맥주만 소개될 뿐 어디에도 중국 맥주에 대한 정보는 나오지 않는 것을 보고 큰 충격을 받았습니다.이를 계기로 그는 인터넷에 호기심이 생겼고 1995년 중국 최초의 인터넷 기업 '차이나옐로페이지'를 만들었습니다. 하지만 얼마 가지 않아 실패하고 말았습니다. 당시 '인터넷'이란 개념을 이해하지 못한 사람들이 그를 사기꾼이라고 비난했기 때문입니다. 하지만 포기하지 않았습니다.이후 1999년 다시 설립한 기업이 바로 '알리바바'입니다. 1점짜리 수학 낙제생이었던 그의 이름은 바로 마윈. 그는 고작 우리 돈 8000만원으로 미국 아마존과 어깨를 나란히 하는 세계 최대 전자상거래업체를 만들었습니다. 단 6분 만에 손정의 소프트뱅크 회장으로부터 2000만달러(약 240억원)를 투자받은 일화는 업계에서 전설처럼 회자되고 있습니다.마윈은 2004년 온라인 쇼핑몰 타오바오에 결제 시스템 '알리페이(ALIPAY)'를 도입했습니다. 당시 중국은 신용카드 보급률이 낮아 거래의 안전성을 확보하기 힘들었습니다. 이 때문에 '제3자 보증 결제 방식'을 택한 것인데요. 구매자가 알리페이에 현금을 입금하면, 상품 수령 후 결제금액이 판매자에 넘어가는 구조로 물품 대금을 못받거나 오배송 사고를 막아주는 역할을 했습니다. 낮은 신용카드 사용률을 극복할 방안으로 모바일 결제를 고안해낸 것입니다.그 결과 알리바바는 14억명 거대한 내수 시장을 기반으로 폭발적인 성장을 하게 됐습니다. 알리페이는 온라인 결제를 포함해 교통 요금, 식당, 마트, 개인 간 송금 등 오프라인 영역 결제까지 광범위한 결제 서비스를 지원하면서 보편화되기 시작했습니다.특히 알리페이에 'QR코드'(2차원 형태의 바코드)를 삽입해 중국이 '현금 없는 사회'로 전환하는데 일조했습니다. 판매자들이 계산대 앞에 QR코드만 부착해 놓으면 카드 단말기 없이도 휴대폰 '스캔'으로 결제가 가능해 인기를 끌었는데요. 길거리 노점상, 공공 자전거 대여, 음료 자판기, 심지어 노숙인들까지 '스캔'을 구걸하는 모습이 화제가 될 만큼 중국인이라면 거의 대부분 갖고 있는 결제 시스템으로 상용화됐습니다.2011년 마윈은 알리페이를 분사하기로 결심했습니다. 중국이 단 1%의 해외자본만 보유하고 있어도 국무원으로부터 '비금융기관 지급서비스' 비준을 받게했기 때문입니다. 사실상 외국자본을 보유한 기업의 페이 시장 진입이 어려워진 것입니다. 소프트뱅크와 야후를 1, 2대 주주로 두고 있던 알리바바는 결국 알리페이를 비롯한 금융 서비스를 '앤트그룹(구 앤트파이낸셜)'이라는 이름으로 바꾸고 분사를 단행하게 됩니다.이같은 결정을 내린 마윈은 다소 난감한 처지에 몰렸는데요. 당시 결정에 대해 마윈 알리바바 전 회장은 "회사 경영자로서 덩샤오핑처럼 행동할 수밖에 없었다"라고 회고했습니다. 이 같은 결정이 대주주와 사전에 상의 없이 독단적으로 했던 것임을 사실상 인정한 것으로 풀이됩니다.우여곡절 끝에 '앤트그룹'으로 분리한 결정은 '신의 한 수'였습니다. 단순 결제 기능을 넘어 자산운용, 소액신용대출, 은행, 보험 등의 상품을 내놓으면서 최근 가장 크게 주목받고 있는 '테크핀(techfin)' 기업으로 성장했기 때문입니다.테크핀은 마윈이 고안한 개념으로 정보기술(IT) 기업이 주도하는 금융 서비스를 의미합니다. 금융사가 IT 기술을 활용해 제공하는 핀테크와는 반대되는 개념입니다. 국내에서도 네이버가 최근 네이버파이낸셜을 설립하고 금융업에 뛰어들고, 카카오가 카카오뱅크와 카카오페이증권 등 금융 계열사를 두고 금융업에 진입하는 것과 맥락을 같이 합니다.마윈은 알리페이를 결제하고 남은 예치금에 대해 이자를 받을 수 있는 머니마켓펀드(MMF) 서비스 '위어바오(余額寶)'를 2013년 내놓았습니다. 은행업을 오래 전부터 염두에 두고 있던 그는 "은행 스스로 바뀌지 않으면 내가 바꾸겠다"라고 말하며 본격적으로 중소상공인들, 이른바 '개미'들을 위한 금융 상품을 잇따라 내놓아 젊은이들을 사로잡았습니다. 이 펀드의 이용자 수는 지난해 6억명을 돌파했습니다. 현재 총자산은 1조1300억위안(약 190조원)으로 세계 최대의 MMF로 성장했습니다.앤트그룹은 알리페이에 안면인식 결제서비스를 2017년 탑재했습니다. 2018년에는 블록체인을 활용해 필리핀 전자지갑 업체 지캐시(GCash)간 실시간 국제 송금 서비스를 개시했습니다. 인공지능(AI), 빅데이터 기술 등을 활용하며 사업을 확대, 수입원을 다각화하고 있습니다.현재 전세계에서 알리페이 서비스를 이용하고 있는 이용자 수는 10억명(지난해 1월 기준)에 달합니다. 알리페이를 보유 중인 앤트그룹은 중국 상하이 증권거래소와 홍콩거래소에 동시 상장을 추진 중입니다. 미 월스트리트저널(WSJ) 등 외신에 따르면 글로벌 투자은행들은 앤트그룹의 기업가치를 약 2000억달러(약 240조원)으로 평가하고 있습니다. 기업공개(IPO) 시장에서 지난해 사상 최대의 기업가치를 평가받았던 사우디아라비아의 '아람코'를 넘어설 것이란 전망이 나오고 있습니다.지난해 아람코는 지분의 1.5%를 공모해 역대 최고 공모금액인 256억달러(약 30조6000억원)를 거둬들여 2014년 알리바바 IPO 기록(250억달러)을 제쳤습니다. 알리바바로부터 분사한지 9년. 금융 자회사 앤트그룹이 이 타이틀을 되찾아올지 관심이 갑니다.조아라 한경닷컴 기자 rrang123@hankyung.com
![中 영어 강사가 키운 기업…9년 만에 시총 240조 '껑충' [조아라의 소프트 차이나]](https://img.hankyung.com/photo/202007/01.23300713.3.jpg)
-
3
세계 항공사 근로자 중 약 40만 명이 신종 코로나바이러스 감염증(코로나19) 사태로 일자리를 잃었거나 실직 위기에 처한 것으로 나타났다.블룸버그통신은 23일(현지시간) 자체 집계 결과 세계 항공사 직원 40만여 명이 이미 해고·일시 해고됐거나 실직 가능성을 통보받았다고 보도했다. 북미에서만 13만 명, 유럽에선 11만7000명가량이 해당한다. 아시아태평양에선 10만2000명, 중동·아프리카에선 5만2000명, 남미에선 3000명가량이다. 블룸버그통신은 “영국 브리티시항공과 독일 루프트한자, 두바이 에미레이트항공, 호주 콴타스항공 등이 이미 수천 명 규모의 감원과 무급휴가 계획을 발표했다”며 “각국 간 입국 제한 조치에다 코로나19 감염 가능성을 우려한 사람들이 비행기를 타지 않으면서 세계 항공사들이 타격을 받았다”고 분석했다. 중동 최대 항공사인 에미레이트항공은 이달에만 직원 9000명을 감원하겠다는 계획을 내놨다.미국 항공사에선 연내 대규모 추가 감원 가능성도 예상된다. 그간 미국 정부가 항공사에 총 500억달러(약 60조900억원) 규모 지원금을 제공하는 대신 직원 고용 유지를 요구했지만, 정부 지원이 끝나는 10월부터는 고용 유지 조항이 사라지기 때문이다.블룸버그통신은 “3대 항공사에서만 연내 실직자 규모가 10만 명을 넘길 수 있다”고 내다봤다. 델타, 유나이티드, 아메리칸 등 항공사 세 곳은 총 3만5000명에게 실직 가능성을 통보한 것으로 알려졌다. 로이터통신에 따르면 아메리칸항공은 “정부의 항공사 임금 지원이 끝나는 10월께 잉여 인력이 20~30% 발생할 것”이라며 “이 때문에 일시 해고할 수 있다”고 직원들에게 지난달 말 밝혔다.코로나19 확산세가 잦아들지 않으면서 거대 항공사들이 운항 재개 계획을 중단하거나 연기한 것도 실업 위기를 가중시킬 전망이다. 월스트리트저널은 “코로나19 재확산에 항공 수요가 다시 고꾸라지고 있다”며 “그나마 타격을 덜 받은 저가 항공사들도 예약 취소가 늘면서 항공편을 줄이려 하고 있다”고 분석했다. 국제항공운송협회는 항공 수요가 꺾이면서 항공기·엔진 제조기업, 공항, 여행사 등 관련 산업에서 사라질 일자리 수가 최대 2500만 개에 달할 것으로 보고 있다.선한결 기자 always@hankyung.com


!['매그니피센트7' 실적 먹구름…지수 혼조 [뉴욕증시 브리핑]](https://timg.hankyung.com/t/560x0/photo/202404/01.36519299.1.jpg)








![AI에게 이렇게 말해보세요 "심호흡 한번 하고 문제를 해결해보자" [WSJ 서평]](https://timg.hankyung.com/t/560x0/photo/202404/01.36512304.3.jpg)